
关于HashMap
一、Java集合容器关系:
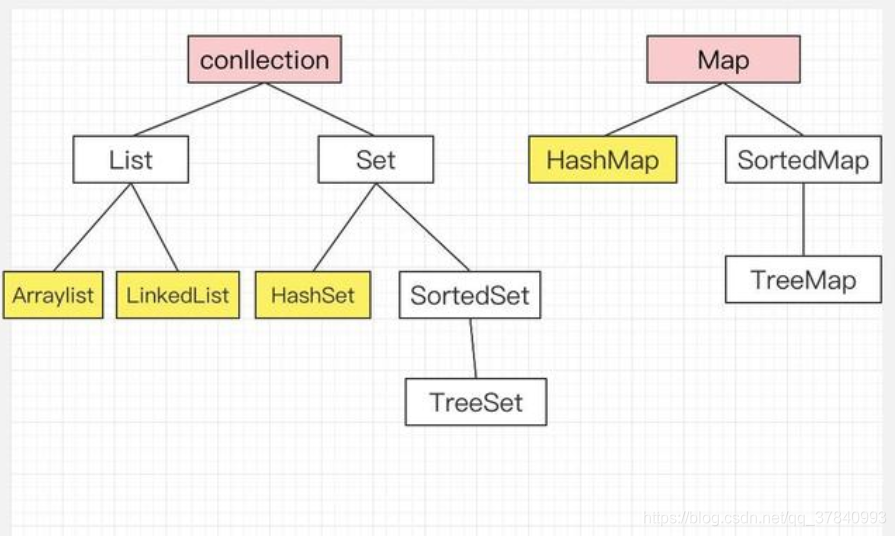
二、Java集合容器详解
我们常见的有集合数据有三种结构:1、数组结构 2、链表结构 3、哈希表结构 下面我们来看看各自的数据结构的特点:
- 数组结构: 存储区间连续、内存占用严重、空间复杂度大
优点: 随机读取和修改效率高,原因是数组是连续的(随机访问性强,查找速度块)
缺点: 插入和删除数据效率低,因插入数据,这个位置后面的数据在内存中都要往后移动,且大小固定不易动态扩展。 - 链表结构: 存储区间离散、占用内存宽松、空间复杂度小
优点: 插入删除速度快,内存利用率高,没有固定大小,扩展灵活
缺点: 不能随机查找,每次都是从第一个开始遍历(查询和修改效率低) - 哈希表结构: 结合数组结构和链表结构的优点,从而实现了查询和修改效率高,插入和删除效率也高的一种数据结构而我们常见的HashMap就是这样的一种数据结构
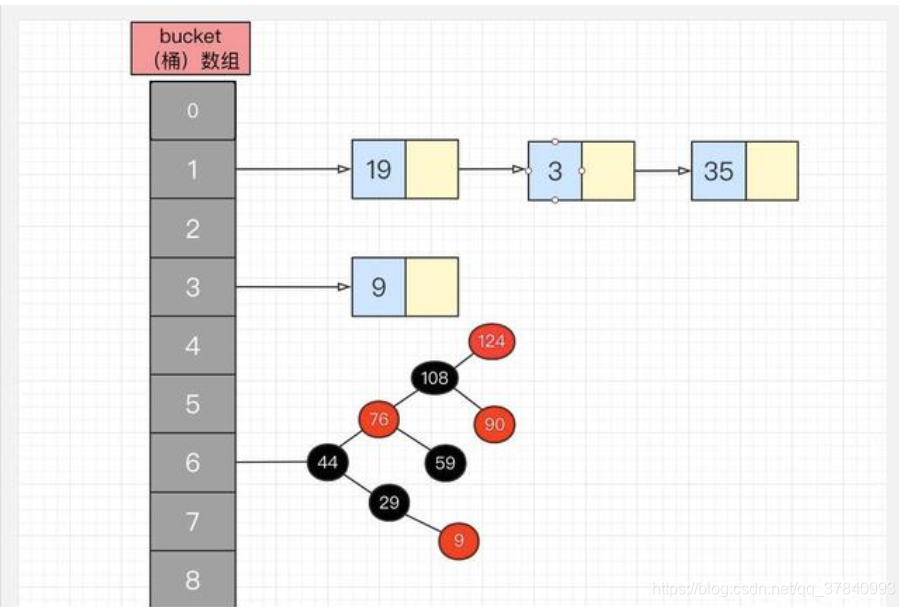
三、HashMap的底层实现
-
JDK1.8之前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列 。HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过
(n - 1) & hash判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。JDK 1.8 HashMap 的 hash 方法源码:
static final int hash(Object key) { int h; // key.hashCode():返回散列值也就是hashcode // ^ :按位异或 // >>>:无符号右移,忽略符号位,空位都以0补齐 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }对比一下 JDK1.7的 HashMap 的 hash 方法源码.
static int hash(int h) { // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
-
JDK1.8之后
相比于之前的版本, JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
-
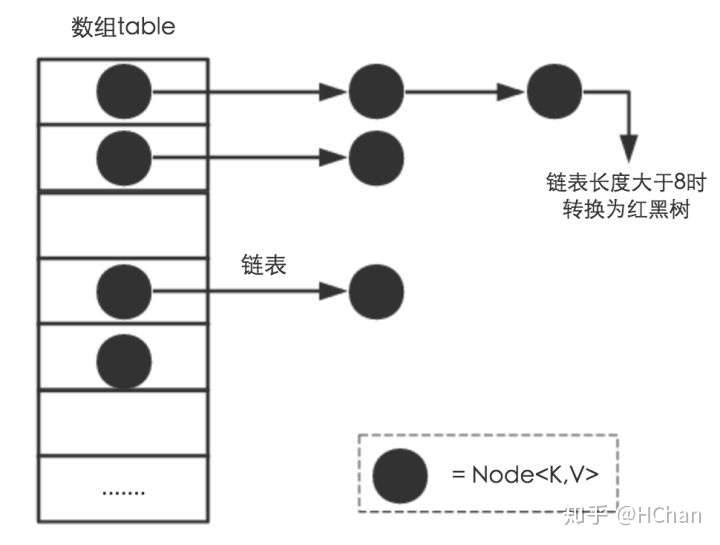
TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
-
推荐阅读:
《Java 8系列之重新认识HashMap》 :https://zhuanlan.zhihu.com/p/21673805
四、HashMap中的put()和get()的实现原理
-
map.put(k,v)实现原理
- 首先将k,v封装到Node对象当中(节点)。
- 然后它的底层会调用K的hashCode()方法得出hash值。
- 通过哈希表函数/哈希算法,将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。
-
map.get(k)实现原理
- 先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。
- 通过上一步哈希算法转换成数组的下标之后,在通过数组下标快速定位到某个位置上。
重点理解:如果这个位置上什么都没有,则返回null。
如果这个位置上有单向链表,那么它就会拿着参数K和单向链表上的每一个节点的K进行equals,如果所有equals方法都返回false,则get方法返回null。
如果其中一个节点的K和参数K进行equals返回true,那么此时该节点的value就是我们要找的value了,get方法最终返回这个要找的value。
五、为何随机增删、查询效率都很高的原因是?
-
原因:
增删是在链表上完成的,而查询只需扫描部分,则效率高。HashMap集合的key,会先后调用两个方法,hashCode and equals方法,这这两个方法都需要重写。
六、为什么放在hashMap集合key部分的元素需要重写equals方法?
因为equals方法默认比较的是两个对象的内存地址
{kind=link}
{kind=link}
 微信
微信
 支付宝
支付宝